
This webpage aims to regroup publications and software produced as part of a joint project at Fraunhofer HHI and TU Berlin on developing new methods to understand nonlinear predictions of state-of-the-art machine learning models. Machine learning models, in particular deep neural networks (DNNs), are characterized by very high predictive power, but in many case, are not easily interpretable by a human. Interpreting a nonlinear classifier is important to gain trust into the prediction, identify potential data selection biases or artefacts, or gaining insights into complex datasets.
Check our Review Paper

W Samek, G Montavon, S Lapuschkin, C Anders, KR Müller Proceedings of the IEEE, 109(3):247-278, 2021
Interactive LRP Demos
Draw a handwritten digit and see the heatmap being formed in real-time. Create your own heatmap for natural images or text. These demos are based on the Layer-wise Relevance Propagation (LRP) technique by Bach et al. (2015).
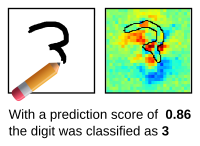
MNIST: A simple LRP demo based on a neural network that predicts handwritten digits and was trained using the MNIST data set.

Caffe: A more complex LRP demo based on a neural network implemented using Caffe. The neural network predicts the contents of the picture.
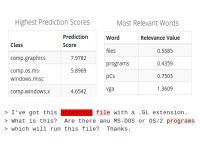
Text: A LRP demo that explains classification on natural language. The neural network predicts the type of document.
How and Why LRP ?
Layer-wise Relevance Propagation (LRP) is a method that identifies important pixels by running a backward pass in the neural network. The backward pass is a conservative relevance redistribution procedure, where neurons that contribute the most to the higher-layer receive most relevance from it. The LRP procedure is shown graphically in the figure below.
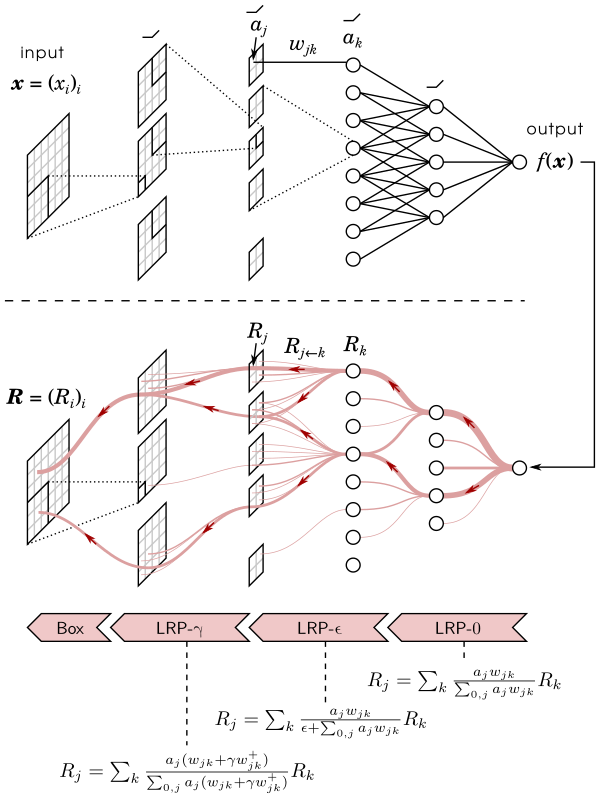
The method can be easily implemented in most programming languages and integrated to existing neural network frameworks. The propagation rules used by LRP can for many architectures, including deep rectifier networks or LSTMs, be understood as a Deep Taylor Decomposition of the prediction.
LRP Software
- Keras Explanation Toolbox (LRP and other Methods)
- GitHub project page for the LRP Toolbox
- TensorFlow LRP Wrapper
- LRP Code for LSTM
- Zennit Pytorch Explanation Toolbox (LRP and other Methods)
- Quantus Toolbox (Evaluation of Explanations)
Tutorials
- XAI Tutorial at ICML 2021
- CVPR Tutorial 2021
- CVPR Tutorial 2018
- Tutorial on Implementing LRP Explainable ML, Applications
- ECML-PKDD 2020 Tutorial (Website | Slides:
1-Intro,
2-Methods,
3-Extensions,
4-Applications)
Explainable ML, Basics and Extensions - ICCV 2019 XAI Workshop Keynote (Website, Slides)
Explainable ML, Applications - EMBC 2019 Tutorial (Slides:
1-Intro,
2-Methods,
3-Evaluation,
4-Applications)
Explainable ML, Medical Applications -
Northern Lights Deep Learning Workshop Keynote (Website | Slides)
Explainable ML, Applications -
2018 Int. Explainable AI Symposium Keynote (Website | Slides)
Explainable ML, Applications - ICIP 2018 Tutorial (Website | Slides:
1-Intro,
2-Methods,
3-Evaluation,
4-Applications)
Explainable ML, Applications - MICCAI 2018 Tutorial (Website | Slides)
Explainable ML, Medical Applications -
Talk at Int. Workshop ML & AI 2018 (Slides)
Deep Taylor Decomposition, Validating Explanations -
WCCI 2018 Keynote (Slides)
Explainable ML, LRP, Applications - GCPR 2017 Tutorial (Slides)
- ICASSP 2017 Tutorial (Slides 1-Intro, 2-Methods, 3-Applications)





Publications


Edited Books
- A Holzinger, R Goebel, R Fong, T Moon, KR Müller, W Samek (Eds.) xxAI - Beyond Explainable AI
Springer LNAI, 13200:1-397, 2022 - W Samek, G Montavon, A Vedaldi, LK Hansen, KR Müller (Eds.) Explainable AI: Interpreting, Explaining and Visualizing Deep Learning
Springer LNCS, 11700:1-439, 2019
Tutorial / Overview Papers
- W Samek, G Montavon, S Lapuschkin, C Anders, KR Müller. Explaining Deep Neural Networks and Beyond: A Review of Methods and Applications
Proceedings of the IEEE, 109(3):247-278, 2021 [preprint, bibtex] - A Holzinger, A Saranti, C Molnar, P Biece, W Samek:. Explainable AI Methods - A Brief Overview
xxAI - Beyond Explainable AI, Springer LNAI, 13200:13-38, 2022 [bibtex] - G Montavon, W Samek, KR Müller. Methods for Interpreting and Understanding Deep Neural Networks
Digital Signal Processing, 73:1-15, 2018 [bibtex] - W Samek, T Wiegand, KR Müller. Explainable Artificial Intelligence: Understanding, Visualizing and Interpreting Deep Learning Models
ITU Journal: ICT Discoveries, 1(1):39-48, 2018 [preprint, bibtex] - W Samek, KR Müller. Towards Explainable Artificial Intelligence
in Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, Springer LNCS, 11700:5-22, 2019 [preprint, bibtex] - G Montavon, A Binder, S Lapuschkin, W Samek, KR Müller. Layer-Wise Relevance Propagation: An Overview
in Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, Springer LNCS, 11700:193-209, 2019 [preprint, bibtex, demo code] - F Klauschen, J Dippel, P Keyl, P Jurmeister, M Bockmayr, A Mock, O Buchstab, M Alber, L Ruff, G Montavon, KR Müller. Toward Explainable Artificial Intelligence for Precision Pathology
Annual Review of Pathology: Mechanisms of Disease 19(1), 2024
Methods Papers
- S Bach, A Binder, G Montavon, F Klauschen, KR Müller, W Samek. On Pixel-wise Explanations for Non-Linear Classifier Decisions by Layer-wise Relevance Propagation
PLOS ONE, 10(7):e0130140, 2015 [preprint, bibtex] - G Montavon, S Lapuschkin, A Binder, W Samek, KR Müller. Explaining NonLinear Classification Decisions with Deep Taylor Decomposition
Pattern Recognition, 65:211–222, 2017 [preprint, bibtex] - M Kohlbrenner, A Bauer, S Nakajima, A Binder, W Samek, S Lapuschkin. Towards best practice in explaining neural network decisions with LRP
Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), 1-7, 2019 [preprint, bibtex] - W Samek, L Arras, A Osman, G Montavon, KR Müller. Explaining the Decisions of Convolutional and Recurrent Neural Networks
Mathematical Aspects of Deep Learning, Cambridge University Press, 229–266, 2022 [preprint, bibtex] - A Binder, G Montavon, S Lapuschkin, KR Müller, W Samek. Layer-wise Relevance Propagation for Neural Networks with Local Renormalization Layers
Artificial Neural Networks and Machine Learning – ICANN 2016, Part II, LNCS, Springer-Verlag, 9887:63-71, 2016 [preprint, bibtex] - PJ Kindermans, KT Schütt, M Alber, KR Müller, D Erhan, B Kim, S Dähne. Learning how to explain neural networks: PatternNet and PatternAttribution
Proceedings of the International Conference on Learning Representations (ICLR), 2018 - L Rieger, P Chormai, G Montavon, LK Hansen, KR Müller. Structuring Neural Networks for More Explainable Predictions
in Explainable and Interpretable Models in Computer Vision and Machine Learning, 115-131, Springer SSCML, 2018 - F Pahde, GÜ Yolcu, A Binder, W Samek, S Lapuschkin. Optimizing Explanations by Network Canonization and Hyperparameter Search
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 3818-3827, 2023 [preprint], bibtex]
Concept-Level Explanations
- R Achtibat, M Dreyer, I Eisenbraun, S Bosse, T Wiegand, W Samek, S Lapuschkin. From "Where" to "What": Towards Human-Understandable Explanations through Concept Relevance Propagation
arXiv:2206.03208, 2022 [preprint, bibtex] - P Chormai, J Herrmann, KR Müller, G Montavon. Disentangled Explanations of Neural Network Predictions by Finding Relevant Subspaces
IEEE Transactions on Pattern Analysis and Machine Intelligence, 14(11):7283-7299, 2024 [bibtex] - M Dreyer, R Achtibat, T Wiegand, W Samek, S Lapuschkin. Revealing Hidden Context Bias in Segmentation and Object Detection through Concept-specific Explanations
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 3828-3838, 2023 [preprint, bibtex]
Explaining Beyond DNN Classifiers
- J Kauffmann, M Esders, L Ruff, G Montavon, W Samek, KR Müller. From Clustering to Cluster Explanations via Neural Networks
IEEE Transactions on Neural Networks and Learning Systems, 35(2):1926-1940, 2024 [demo code, bibtex] - S Letzgus, P Wagner, J Lederer, W Samek, KR Müller, G Montavon. Toward Explainable AI for Regression Models: A Methodological Perspective
IEEE Signal Processing Magazine, 39(4):40-58, 2022 [bibtex] - T Schnake, O Eberle, J Lederer, S Nakajima, K T. Schütt, KR Müller, G Montavon. Higher-Order Explanations of Graph Neural Networks via Relevant Walks
IEEE Transactions on Pattern Analysis and Machine Intelligence 44(11):7581-7596, 2022 [demo code, bibtex] - O Eberle, J Büttner, F Kräutli, KR Müller, M Valleriani, G Montavon. Building and Interpreting Deep Similarity Models
IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(3):1149-1161, 2022 [bibtex] - J Kauffmann, KR Müller, G Montavon. Towards Explaining Anomalies: A Deep Taylor Decomposition of One-Class Models
Pattern Recognition, 101, 107198, 2020 [bibtex] - A Ali, T Schnake, O Eberle, G Montavon, KR Müller, L Wolf. XAI for Transformers: Better Explanations through Conservative Propagation
International Conference on Machine Learning (ICML), 2022 [code, bibtex] - P Xiong, T Schnake, G Montavon, KR Müller, S Nakajima. Efficient Computation of Higher-Order Subgraph Attribution via Message Passing
International Conference on Machine Learning (ICML), 2022 [code, bibtex] - G Montavon, J Kauffmann, W Samek, KR Müller. Explaining the Predictions of Unsupervised Learning Models
xxAI - Beyond Explainable AI, Springer LNAI, 13200:117-138, 2022 [preprint, bibtex] - L Arras, J Arjona, M Widrich, G Montavon, M Gillhofer, KR Müller, S Hochreiter, W Samek. Explaining and Interpreting LSTMs
in Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, Springer LNCS, 11700:211-238, 2019 [preprint, bibtex] - F Bley, S Lapuschkin, W Samek, G Montavon. Explaining Predictive Uncertainty by Exposing Second-Order Effects
Pattern Recognition, 111171, 2024 - F Rezaei Jafari, G Montavon, KR Müller, O Eberle. MambaLRP: Explaining Selective State Space Sequence Models
NeurIPS, 2024 [bibtex]
Evaluation of Explanations
- L Arras, A Osman, W Samek. CLEVR-XAI: A Benchmark Dataset for the Ground Truth Evaluation of Neural Network Explanations
Information Fusion, 81:14-40, 2022 [preprint, bibtex] - A Binder, L Weber, S Lapuschkin, G Montavon, KR Müller, W Samek. Shortcomings of Top-Down Randomization-Based Sanity Checks for Evaluations of Deep Neural Network Explanations
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 16143-16152, 2023 [preprint, bibtex] - W Samek, A Binder, G Montavon, S Bach, KR Müller. Evaluating the Visualization of What a Deep Neural Network has Learned
IEEE Transactions on Neural Networks and Learning Systems, 28(11):2660-2673, 2017 [preprint, bibtex] - L Arras, A Osman, KR Müller, W Samek. Evaluating Recurrent Neural Network Explanations
Proceedings of the ACL Workshop on BlackboxNLP, 113-126, 2019 [preprint, bibtex] - G Montavon. Gradient-Based Vs. Propagation-Based Explanations: An Axiomatic Comparison
in Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, Springer LNCS, 11700:253-265, 2019 [bibtex] - A Hedström, P Bommer, KK Wickstrøm, W Samek, S Lapuschkin, MMC Höhne The Meta-Evaluation Problem in Explainable AI: Identifying Reliable Estimators with MetaQuantus
Transactions on Machine Learning Research, 2023 [preprint, bibtex]
Model Validation and Improvement
- S Lapuschkin, S Wäldchen, A Binder, G Montavon, W Samek, KR Müller. Unmasking Clever Hans Predictors and Assessing What Machines Really Learn
Nature Communications, 10:1096, 2019 [preprint, bibtex] - S Lapuschkin, A Binder, G Montavon, KR Müller, W Samek. Analyzing Classifiers: Fisher Vectors and Deep Neural Networks
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2912-2920, 2016 [preprint, bibtex] - CJ Anders, L Weber, D Neumann, W Samek, KR Müller, S Lapuschkin.
Finding and Removing Clever Hans: Using Explanation Methods to Debug and Improve Deep Models
Information Fusion, 77:261-295, 2022 [preprint, bibtex] - L Weber, S Lapuschkin, A Binder, W Samek. Beyond Explaining: Opportunities and Challenges of XAI-Based Model Improvement
Information Fusion, 92:154-176, 2023 [preprint, bibtex] - J Sun, S Lapuschkin, W Samek, A Binder. Explain and Improve: LRP-Inference Fine Tuning for Image Captioning Models
Information Fusion, 77:233-246, 2022 [preprint, bibtex] - F Pahde, L Weber, CJ Anders, W Samek, S Lapuschkin. PatClArC: Using Pattern Concept Activation Vectors for Noise-Robust Model Debugging
arXiv:2202.03482, 2022 [preprint, bibtex] - F Pahde, M Dreyer, W Samek, S Lapuschkin. Reveal to Revise: An Explainable AI Life Cycle for Iterative Bias Correction of Deep Models
Proceedings of the International Conference on Information Processing in Medical Imaging (MICCAI), 2023 [preprint, bibtex] - J Sun, S Lapuschkin, W Samek, Y Zhao, NM Cheung, A Binder.
Explanation-Guided Training for Cross-Domain Few-Shot Classification
Proceedings of the 25th International Conference on Pattern Recognition (ICPR), 7609-7616, 2021 [preprint, bibtex] - L Linhardt, KR Müller, G Montavon. Preemptively Pruning Clever-Hans Strategies in Deep Neural Networks
Information Fusion, 103:102094, 2024 [bibtex] - J Kauffmann, J Dippel, L Ruff, W Samek, KR Müller, G Montavon. Explainable AI reveals Clever Hans effects in unsupervised learning models
Nature Machine Intelligence, 2025 [bibtex] - J Kauffmann, L Ruff, G Montavon, KR Müller. The Clever Hans Effect in Anomaly Detection
arXiv:2006.10609, 2020
Application to Sciences & Humanities
- I Sturm, S Bach, W Samek, KR Müller. Interpretable Deep Neural Networks for Single-Trial EEG Classification
Journal of Neuroscience Methods, 274:141–145, 2016 [preprint, bibtex] - M Hägele, P Seegerer, S Lapuschkin, M Bockmayr, W Samek, F Klauschen, KR Müller, A Binder. Resolving Challenges in Deep Learning-Based Analyses of Histopathological Images using Explanation Methods
Scientific Reports, 10:6423, 2020 [preprint, bibtex] - A Binder, M Bockmayr, M Hägele, S Wienert, D Heim, K Hellweg, A Stenzinger, L Parlow, J Budczies, B Goeppert, D Treue, M Kotani, M Ishii, M Dietel, A Hocke, C Denkert, KR Müller, F Klauschen. Towards computational fluorescence microscopy: Machine learning-based integrated prediction of morphological and molecular tumor profiles
Nature Machine Intelligence, 3:355-366, 2021 [preprint, bibtex] - F Horst, S Lapuschkin, W Samek, KR Müller, WI Schöllhorn. Explaining the Unique Nature of Individual Gait Patterns with Deep Learning
Scientific Reports, 9:2391, 2019 [preprint, bibtex] - D Slijepcevic, F Horst, B Horsak, S Lapuschkin, AM Raberger, A Kranzl, W Samek, C Breiteneder, WI Schöllhorn, M Zeppelzauer. Explaining Machine Learning Models for Clinical Gait Analysis
ACM Transactions on Computing for Healthcare, 3(2):1-21, 2022 [preprint], bibtex] - AW Thomas, HR Heekeren, KR Müller, W Samek. Analyzing Neuroimaging Data Through Recurrent Deep Learning Models
Frontiers in Neuroscience, 13:1321, 2019 [preprint, bibtex] - P Seegerer, A Binder, R Saitenmacher, M Bockmayr, M Alber, P Jurmeister, F Klauschen, KR Müller. Interpretable Deep Neural Network to Predict Estrogen Receptor Status from Haematoxylin-Eosin Images
Artificial Intelligence and Machine Learning for Digital Pathology, Springer LNCS, 12090, 16-37, 2020 [bibtex] - SM Hofmann, F Beyer, S Lapuschkin, O Goltermann, M Loeffler, KR Müller, A Villringer, W Samek, AV Witte. Towards the Interpretability of Deep Learning Models for Multi-Modal Neuroimaging: Finding Structural Changes of the Ageing Brain
NeuroImage, 261:119504, 2022 [bibtex] - P Keyl, M Bockmayr, D Heim, G Dernbach, G Montavon, KR Müller, F Klauschen. Patient-level proteomic network prediction by explainable artificial intelligence NPJ Precis Oncol. 6(1):35, 2022 [bibtex]
- P Keyl, P Bischoff, G Dernbach, M Bockmayr, R Fritz, D Horst, N Blüthgen, G Montavon, KR Müller, F Klauschen. Single-cell gene regulatory network prediction by explainable AI Nucleic Acids Research, gkac1212, 2023 [bibtex]
- H El-Hajj, O Eberle, A Merklein, A Siebold, N Schlomi, J Büttner, J Martinetz, KR Müller, G Montavon, M Valleriani. Explainability and transparency in the realm of digital humanities: toward a historian XAI
International Journal of Digital Humanities, 2023 [bibtex] - O Eberle, J Büttner, H El-Hajj, G Montavon, KR Müller, M Valleriani. Historical insights at scale: A corpus-wide machine learning analysis of early modern astronomic tables
Science Advances 10 (43), eadj1719, 2024
Application to Text
- L Arras, F Horn, G Montavon, KR Müller, W Samek. "What is Relevant in a Text Document?": An Interpretable Machine Learning Approach
PLOS ONE, 12(8):e0181142, 2017 [preprint, bibtex] - L Arras, G Montavon, KR Müller, W Samek. Explaining Recurrent Neural Network Predictions in Sentiment Analysis
Proceedings of the EMNLP Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis, 159-168, 2017 [preprint, bibtex] - L Arras, F Horn, G Montavon, KR Müller, W Samek. Explaining Predictions of Non-Linear Classifiers in NLP
Proceedings of the ACL Workshop on Representation Learning for NLP, 1-7, 2016 [preprint, bibtex] - F Horn, L Arras, G Montavon, KR Müller, W Samek. Exploring text datasets by visualizing relevant words
arXiv:1707.05261, 2017
Application to Images & Faces
- S Lapuschkin, A Binder, KR Müller, W Samek. Understanding and Comparing Deep Neural Networks for Age and Gender Classification
Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), 1629-1638, 2017 [preprint, bibtex] - C Seibold, W Samek, A Hilsmann, P Eisert. Accurate and Robust Neural Networks for Face Morphing Attack Detection
Journal of Information Security and Applications, 53:102526, 2020 [preprint, bibtex] - S Bach, A Binder, KR Müller, W Samek. Controlling Explanatory Heatmap Resolution and Semantics via Decomposition Depth
Proceedings of the IEEE International Conference on Image Processing (ICIP), 2271-2275, 2016 [preprint, bibtex] - A Binder, S Bach, G Montavon, KR Müller, W Samek. Layer-wise Relevance Propagation for Deep Neural Network Architectures
Proceedings of the 7th International Conference on Information Science and Applications (ICISA), 6679:913-922, Springer Singapore, 2016 [preprint, bibtex] - F Arbabzadah, G Montavon, KR Müller, W Samek. Identifying Individual Facial Expressions by Deconstructing a Neural Network
Pattern Recognition - 38th German Conference, GCPR 2016, Lecture Notes in Computer Science, 9796:344-354, 2016 [preprint, bibtex]
Application to Video
- C Anders, G Montavon, W Samek, KR Müller. Understanding Patch-Based Learning of Video Data by Explaining Predictions
in Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, Springer LNCS 11700:297-309, 2019 [preprint, bibtex] - V Srinivasan, S Lapuschkin, C Hellge, KR Müller, W Samek. Interpretable human action recognition in compressed domain
Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1692-1696, 2017 [preprint, bibtex]
Application to Speech
- A Frommholz, F Seipel, S Lapuschkin, W Samek, J Vielhaben. XAI-based Comparison of Input Representations for Audio Event Classification
Proceedings of the 20th International Conference on Content-based Multimedia Indexing, 2023 [preprint, bibtex] - J Vielhaben, S Lapuschkin, G Montavon, W Samek. Explainable AI for Time Series via Virtual Inspection Layers
Pattern Recognition, 110309, 2024 [preprint] - S Becker, M Ackermann, S Lapuschkin, KR Müller, W Samek. Interpreting and Explaining Deep Neural Networks for Classification of Audio Signals
arXiv:1807.03418, 2018
Application to Neural Network Pruning
- S Ede, S Baghdadlian, L Weber, A Nguyen, D Zanca, W Samek, S Lapuschkin.
Explain to Not Forget: Defending Against Catastrophic Forgetting with XAI
Machine Learning and Knowledge Extraction. CD-MAKE 2022, LNCS, 13480:1-18, 2022 [preprint, bibtex]
- D Becking, M Dreyer, W Samek, K Müller, S Lapuschkin.
ECQx: Explainability-Driven Quantization for Low-Bit and Sparse DNNs
xxAI - Beyond Explainable AI, Springer LNAI, 13200:271-296, 2022 [preprint, bibtex]
- S Yeom, P Seegerer, S Lapuschkin, A Binder, S Wiedemann, KR Müller, W Samek.
Pruning by Explaining: A Novel Criterion for Deep Neural Network Pruning
Pattern Recognition, 115:107899, 2021 [preprint, bibtex]
Interpretability and Causality
- A Rieckmann, P Dworzynski, L Arras, S Lapuschkin, W Samek, OA Arah, NH Rod, CT Ekstrom.
Causes of Outcome Learning: A causal inference-inspired machine learning approach to disentangling common combinations of potential causes of a health outcome
International Journal of Epidemiology, dyac078, 2022 [preprint, bibtex]
Software Papers
- A Hedström, L Weber, D Bareeva, F Motzkus, W Samek, S Lapuschkin, MMC Höhne Quantus: An Explainable AI Toolkit for Responsible Evaluation of Neural Network Explanation
Journal of Machine Learning Research, 24(34):1-11, 2023 [preprint, bibtex] - CJ Anders, D Neumann, W Samek, KR Müller, S Lapuschkin Software for Dataset-wide XAI: From Local Explanations to Global Insights with Zennit, CoRelAy, and ViRelAy
arXiv:2106.13200, 2021 [preprint, bibtex] - M Alber, S Lapuschkin, P Seegerer, M Hägele, KT Schütt, G Montavon, W Samek, KR Müller, S Dähne, PJ Kindermans iNNvestigate neural networks!
Journal of Machine Learning Research, 20(93):1−8, 2019 [preprint, bibtex] - M Alber. Software and Application Patterns for Explanation Methods
in Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, Springer LNCS, 11700:399-433, 2019 [bibtex] - S Lapuschkin, A Binder, G Montavon, KR Müller, W Samek The Layer-wise Relevance Propagation Toolbox for Artificial Neural Networks
Journal of Machine Learning Research, 17(114):1−5, 2016 [preprint, bibtex]
Downloads
BVLC Model Zoo Contributions
- Pascal VOC 2012 Multilabel Model (see paper): [caffemodel] [prototxt]
- Age and Gender Classification Models (see paper): [data and models]
Impressum